목차
<SQL> 조인 개요 및 조인 시 데이터 집합 레벨의 변화 이해
- <3개의 테이블을 조인하는 경우>
- <to_date('날짜', '형식') 함수 사용>
- <with 함수>
- <두 개의 문자열을 합치기>
<SQL> Join의 여러 유형
- <Outer Join>
- <coalesce 함수 사용하기>
- <Non Equi Join> - join 연산에 바로 사용 가능하다!!
- <Cross Join (Cartesian Product Join)>
<SQL> Date, TimeStamp, Interval 다루기
- <문자열을 Date, Timestamp로 변환>
- <Date, Timestamp를 문자열로 변환>
- <extract와 date_part를 이용하여 Date/TimeStamp에서 년/월/일/시간/분/초 추출>
- <Interval를 활용한 날짜와 시간 연산>
- <현재 시간을 나타내는 함수>
- <Justify_interval vs. age 함수>
<SQL> Group By와 집계함수
- <집계함수>
- <Group by 절에 가공 컬럼 및 case when 적용>
- <Case 문>
- <Group by 절에 case when 적용>
- <Group by와 Aggregate 함수의 case when을 이용한 Pivoting>
- <Group by Rollup>
- <Group by Cube>
<SQL> 조인 개요 및 조인 시 데이터 집합 레벨의 변화 이해
조인 - 서로 다른 테이블을 연결
JOIN 연산을 수행할 때, 유의해야 하는 사항!
→ 조인 시 데이터 집합 레벨의 변화를 알아야 한다.
1:M 조인 시 결과 집합은 M 집합의 레벨을 그대로 유지한다!
조인 컬럼 {$컬럼명} 기준 M 집합 = 해당 컬럼 안에 중복된 값이 있다.
조인 컬럼 {$컬럼명} 기준 1 집합 = 해당 컬럼 안에 값이 Unique 하다.
[테이블 관계]

<3개의 테이블을 조인하는 경우>

-- 부서명 SALES와 RESEARCH의 소속 직원들의 부서명, 직원번호, 직원명, JOB 그리고 과거 급여 정보 추출
select a.deptno, a.empno, a.ename, a.job, a.sal
from hr.emp a
join hr.dept b on a.deptno = b.deptno
where b.dname in ('SALES', 'RESEARCH')
--과거 급여에 대한 정보를 뽑아야 하기 때문에 3개의 테이블을 조인해야 한다.
select a.dname, b.empno, b.ename, b.job, c.fromdate, c.todate, c.sal
from hr.dept a
join hr.emp b on a.deptno = b.deptno
--관계 레벨은 hr.emp_salary_hist를 따라간다
join hr.emp_salary_hist c on b.empno = c.empno
where a.dname in('SALES', 'RESEARCH')관계 레벨에 대한 이해가 필요하다!!
<to_date('날짜', '형식') 함수 사용>
날짜 형식 변환 to_date('20230730', 'yyyymmdd')
-- 부서명 SALES와 RESEARCH의 소속 직원들의 부서명, 직원번호, 직원명, JOB 그리고 과거 급여 정보중 1983년 이전 데이터는 무시하고 데이터 추출
select a.dname, b.empno, b.ename, b.job, c.fromdate, c.todate, c.sal
from hr.dept a
join hr.emp b on a.deptno = b.deptno
join hr.emp_salary_hist c on b.empno = c.empno
where a.dname in('SALES', 'RESEARCH')
and fromdate >= to_date('19830101', 'yyyymmdd')
order by a.dname, b.empno, c.fromdate;https://learn.microsoft.com/ko-kr/azure/databricks/sql/language-manual/functions/to_date
to_date 함수 - Azure Databricks - Databricks SQL
Databricks SQL 및 Databricks Runtime에서 SQL 언어의 to_date 함수 구문을 알아봅니다.
learn.microsoft.com
<with 함수>
with 절을 통해 임의의 테이블을 만들어서 활용할 수 있다
with
temp_01 as (
select * from hr.emp where deptno = 30
),
temp_02 as (
select * from hr.dept where deptno = 30
)
select a.*, b.dname, b.loc from temp_01 a
join temp_02 b on a.deptno = b.deptno<두 개의 문자열을 합치기>

우선 해당 코드에서 관계 레벨은 nw.orders를 따라감 (왜냐하면 쟤가 M이기 때문이다!)
-- Berlin에 살고 있는 고객이 주문한 주문 정보를 구할것
-- 고객명, 주문id, 주문일자, 주문접수 직원명, 배송업체명을 구할것.
select c.contact_name, o.order_id, o.order_date, e.first_name||' '||e.last_name as employee_name, s.company_name
from nw.customers c
join nw.orders o on c.customer_id = o.customer_id
join nw.employees e on o.employee_id = e.employee_id
join nw.shippers s on o.ship_via = s.shipper_id
where c.city = 'Berlin'
;- concat 함수 사용
- 단순하게 두 문자열을 합칠 때는 좋지만, 중간에 띄어쓰기가 들어가야 하면 함수를 두번 써야 해서 귀찮아진다.
- 사용법: concat(문자열 1, 문자열 2)
- https://www.w3resource.com/oracle/character-functions/oracle-concat-function.php
- || 사용
- 위에서 사용한 것과 같이 합치고 싶은 문자열 사이에 잘 넣어주면 된다
<SQL> JOIN의 여러 유형
- Inner Join과 Join은 같다고 생각하자!
- Inner Join / Left (Outer) Join / Full Outer Join
<Outer Join>
(1)
-- 주문이 단 한번도 없는 고객 정보 구하기.
-- outer 조인을 사용하면 정합성에 대한 것을 빠르게 확인 가능!
select c.*, o.*
from nw.customers c
left outer join nw.orders o on c.customer_id = o.customer_id
where o.order_id is null;주문이 한 번도 들어오지 않았다는 것을 outer join과 null 값을 통해 확인이 가능하다.
(2)
-- Madrid에 살고 있는 고객이 주문한 주문 정보를 구할것.
-- 고객명, 주문id, 주문일자, 주문접수 직원명, 배송업체명을 구하되,
-- 만일 고객이 주문을 한번도 하지 않은 경우라도 고객정보는 빠지면 안됨. 이경우 주문 정보가 없으면 주문id를 0으로 나머지는 Null로 구할것.
select c.contact_name, coalesce(o.order_id, 0) as order_id, o.order_date, e.first_name||' '||e.last_name as employee_name
from customers c
left join orders o ON c.customer_id = o.customer_id
left join employees e on o.employee_id = e.employee_id
left join shippers s on s.shipper_id = o.ship_via
where c.city = 'Madrid'Left Join에서 먼저 오는 테이블은 "빠지면 안됨"과 같은 조건이 붙은 테이블이다!
(위에 예제에서는 '고객 정보는 빠지면 안됨'이라고 되어 있기 때문에, 고객 테이블이 먼저 와야 한다)
만약에 모든 테이블에 대해 정보가 하나라도 빠지면 안된다고 하면..! full outer join을 써야 함
<coalesce 함수 사용하기>
Syntax : COALESCE(val1, val2, ...., val_n) [병합하다]
복잡하게 생각하기 보단, NULL 값이 발생하는 것을 방지하기 위해 인자로 주어진 컬럼들 중 NULL이 아닌 값을 리턴한다.
SELECT COALESCE(NULL,1,2);
//result : 1
SELECT COALESCE(NULL,NULL,2);
//result : 2
SELECT COALESCE(1,2,NULL);
//result : 1
SELECT COALESCE(o.order_id, 0);
//order_id 컬럼에 NULL 값이 있으면 NULL 대신 0으로 값을 리턴
https://www.w3schools.com/sql/func_sqlserver_coalesce.asp
SQL Server COALESCE() Function
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
<Non Equi Join> - join 연산에 바로 사용 가능하다!!
키 값으로 연결 시 =이 아닌 다른 연산자(between, >, >=, <, <=)를 사용하는 조인
Between 연산을 사용할 때 유용하게 활용 가능하다!!
-- 직원정보와 급여등급 정보를 추출.
select e.*, s.grade as salgrade, s.losal, s.hisal
from emp e
join salgrade s on e.sal between s.losal and s.hisal
<Cross Join (Cartesian Product Join)>
select a.*, b.* from table a cross join b테이블의 모든 행에 대해 연산이 이루어진다. 그냥 다 곱해~로 알고 있는 그 친구
<SQL> Date, TimeStamp, Interval 다루기
- Date : 일자로서 년, 월, 일 정보 YYYY_MM-DD
- Timestamp : 일자를 시간 정보까지 같이 가짐 YYYY-MM-DD HH24:MI:SS
- Time : 오직 시간 정보
- Interval : N days HH24:MI:SS
<문자열을 Date, Timestamp로 변환>
- to_date(‘2022-01-01’, ‘yyyy-mm-dd’) // 2022-01-01
- to_timestamp('2022-01-01', 'yyyy-mm-dd') // 2022-01-01 00:00:00.000 +0900
- to_timestamp('2022-01-01 14:36:52', 'yyyy-mm-dd hh24:mi:ss') // 2022-01-01 14:36:52.000 +0900
<Date, Timestamp를 문자열로 변환>
- to_char(hiredate, ‘yyyy-mm-dd’) // 1980-12-17
| 포맷팅 패턴 | 내용 | 포맷팅 패턴 | 내용 |
| hh24 | 하루중 시간(00-23) | month | 월 이름 |
| hh12 | 하루중 시간(01-12) | day | 요일 이름 |
| mi | 분(00-59) | w | 월의 주(1-5) |
| ss | 초(00-59) | ww | 년의 주(1-52) |
| yyyy | 년도 | d | 요일 일(1)-토(7) |
| mm | 월(01-12) | am 또는 pm | AM.PM 표시 |
| dd | 일(월중 일자 01-31) | tz | 시간대 |
<extract와 date_part를 이용하여 Date/TimeStamp에서 년/월/일/시간/분/초 추출>
select a.*
, extract(year from hiredate) as year
, extract(month from hiredate) as month
, extract(day from hiredate) as day
from hr.emp a;
select a.*
, date_part('year', hiredate) as year
, date_part('month', hiredate) as month
, date_part('day', hiredate) as day
from hr.emp a;<Interval를 활용한 날짜와 시간 연산>
- Date 타입에 숫자값을 더하거나/빼면 숫자값에 해당하는 일자를 더하거나/빼서 날짜 계산.
- select to_date('2022-01-01', 'yyyy-mm-dd') + 2
- Timestamp 타입에 숫자값을 더하거나 빼면 오류 발생. → interval 타입을 이용하여 연산 수행
- select to_timestamp('2022-01-01 14:36:52', 'yyyy-mm-dd hh24:mi:ss') + interval '7 hour'
- select to_date('2022-01-01', 'yyyy-mm-dd') + interval '7 hour'도 가능하다! But, Timestamp로 반환된다
- Date 혹은 Interval 간에 뺄셈 연산도 가능하다
- Date 간의 차이는 정수형으로 반환되고, Timestamp 간의 차이는 Interval로 반환된다.
-- 날짜 간의 차이 구하기. 차이값은 정수형.
select to_date('2022-01-03', 'yyyy-mm-dd') - to_date('2022-01-01', 'yyyy-mm-dd') as interval_01;
-- Timestamp간의 차이 구하기. 차이값은 interval
select to_timestamp('2022-01-01 14:36:52', 'yyyy-mm-dd hh24:mi:ss')
- to_timestamp('2022-01-01 12:36:52', 'yyyy-mm-dd hh24:mi:ss') as time_01;<현재 시간을 나타내는 함수>
now(), current_timestamp, current_date, current_time을 사용할 수 있다.

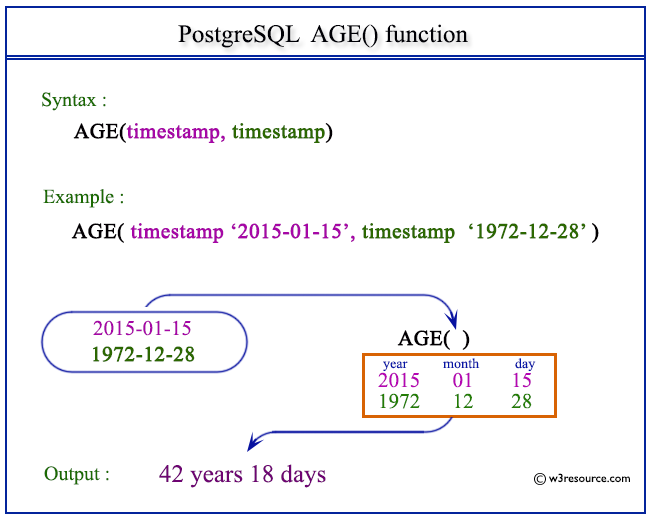
<Justify_interval vs. age 함수>
- Justify_interval
- 한 달을 30일로 두고 계산을 진행함
- age
- 현재의 시간을 사용한다는 점과 날짜를 실제를 기반으로 정확하게 연산함

<date_trunc 함수>
절삭 혹은 초기화 함수라고 생각하면 된다.
select trunc(99.9999, 2); // 99.99
--date_trunc는 주어진 인자를 기준으로 초기화
select date_trunc('month', '2023-03-03'::date)::date; // 2023-03-01
-- date타입을 date_trunc해도 반환값은 timestamp타입
select date_trunc('month', to_date('2022-03-03', 'yyyy-mm-dd')); // 2023-03-01 00:00:00.000 +0900
-- 만약 date 타입을 그대로 유지하려면 ::date로 명시적 형변환 필요
select date_trunc('month', '2023-03-03'::date)::date; // 2023-03-01주 단위 혹은 월 단위에서 시작 날짜나 마지막 날짜를 구할 수 있다.
-- week의 시작 날짜 구하기. 월요일 기준.
select date_trunc('week', '2022-03-03'::date)::date;
-- week의 마지막 날짜 구하기. 월요일 기준(일요일이 마지막 날짜)
select (date_trunc('week', now()::date) + interval '6 days')::date;
-- week의 시작 날짜 구하기. 일요일 기준.
select date_trunc('week', '2022-03-03'::date)::date -1;
-- week의 마지막 날짜 구하기. 일요일 기준(토요일이 마지막 날짜)
select (date_trunc('week', '2022-03-03'::date)::date - 1 + interval '6 days')::date;
-- month의 마지막 날짜
select (date_trunc('month', '2022-03-03'::date) + interval '1 month' - interval '1 day')::date;
-- 시간에 대해서도 date_trunc 함수 사용 가능.
select date_trunc('hour', now());Group by 함수와도 자주 사용된다.
-- 입사월로 group by
select date_trunc('month', hiredate) as hire_month, count(*)
from hr.emp_test
group by date_trunc('month', hiredate);
-- 시분초가 포함된 입사일일 경우 시분초를 절삭한 값으로 group by
select date_trunc('day', hiredate) as hire_day, count(*)
from hr.emp_test
group by date_trunc('day', hiredate);<SQL> Group By와 집계함수
Group By 함수를 사용할 때 유의해야 하는 점은 select 다음에 오는 요소가 group by 절 내에 있는 요소이거나 집계 함수 내에서 사용 되어야 한다.!
-- 부서명 SALES와 RESEARCH 소속 직원별로 과거부터 현재까지 모든 급여를 취합한 평균 급여
select e.empno, e.ename, round(avg(esh.sal),2)
from emp e
join emp_salary_hist esh on e.empno = esh.empno
join dept d on e.deptno = d.deptno
where d.dname in('SALES', 'RESEARCH')
group by e.empno예를 들어서 위의 예제에서 사실 select 뒤에 올 수 있는 요소는 1) e.empno - group by 절 내에 있는 요소 2) round(avg(esh.sal),2) - 집계함수 이다!! 만약에서 e.ename을 쓰고 싶다면 max(e.ename) as ename 처럼 사용해야 한다!
-- 부서명 SALES와 RESEARCH 소속 직원별로 과거부터 현재까지 모든 급여를 취합한 평균 급여
select e.empno, max(e.ename) as ename, round(avg(esh.sal),2)
from emp e
join emp_salary_hist esh on e.empno = esh.empno
join dept d on e.deptno = d.deptno
where d.dname in('SALES', 'RESEARCH')
group by e.empno<집계 함수>
- 집계 함수는 Null을 계산하지 않는다. - 특히 avg에서!!
- Min, Max 함수의 경우 숫자값 뿐만 아니라 문자열 / 날짜 / 시간형도 가능하다.
<Group by 절에 가공 컬럼 및 case when 적용>
group by 절 안에 여러 함수를 활용해서 범위를 나누어주거나 원하는 조건을 넣어줄 수 있다.
-- 1000미만, 1000-1999, 2000-2999와 같이 1000단위 범위내에 sal이 있는 레벨로 group by 하고 해당 건수를 구함.
select floor(sal/1000)*1000, count(*)
from hr.emp
group by floor(sal/1000)*1000;그리고 항상 group by 절 내에 있는 요소와 집계함수만이 select 문에 사용될 수 있다.
<Case 문>
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
select *, case when job='SALESMAN' then sal else 0 end
from hr.emp
--else로 별도의 조건을 지정하지 않았기 때문에 sal 값이 없으면 자동으로 NULL 값이 들어간다.
select *, case when job='SALESMAN' then sal end as sales_sal
, case when job='MANAGER' then sal end as manager_sal
from hr.emphttps://www.w3schools.com/sql/sql_case.asp
SQL CASE Expression
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
<Group by 절에 case when 적용>
case when을 group by 절 안에 활용할 수 있다. → 그룹에 대한 조건을 반영해야 할 때 유용하다
-- job이 SALESMAN인 경우와 그렇지 않은 경우만 나누어서 평균/최소/최대 급여를 구하기.
select case when job = 'SALESMAN' then 'SALESMAN'
else 'OTHERS' end as job
, avg(sal) as avg_sal, max(sal) as max_sal, min(sal) as min_sal --, count(*) as cnt
from hr.emp
group by case when job = 'SALESMAN' then 'SALESMAN'
else 'OTHERS' end ;
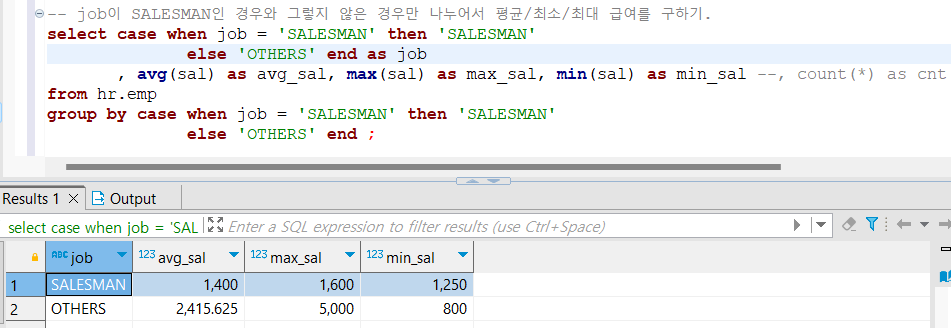
기존에 직무는 SALESMAN, CLERK, MANAGER 등 다양한 분류가 있었지만, 조건에 따라서 특정 직무와 나머지로 구분해서 데이터를 처리할 수 있다!!
<Group by와 Aggregate 함수의 case when을 이용한 Pivoting>

Select Year
, sum(case when Month = 1 then revenue end) as Jan
, sum(case when Month = 2 then revenue end) as Feb
, sum(case when Month = 3 then revenue end) as Mar
………………
, sum(case when Month = 12 then revenue end) as Dec
From sales
Group by Year

-- group by Pivoting시 조건에 따른 건수 계산 유형(count case when then 1 else null end)
select deptno, count(*) as cnt
, count(case when job = 'SALESMAN' then 1 end) as sales_cnt
, count(case when job = 'MANAGER' then 1 end) as manager_cnt
, count(case when job = 'ANALYST' then 1 end) as analyst_cnt
, count(case when job = 'CLERK' then 1 end) as clerk_cnt
, count(case when job = 'PRESIDENT' then 1 end) as president_cnt
from emp
group by deptno;
-- group by Pivoting시 조건에 따른 건수 계산 시 잘못된 사례(count case when then 1 else null end)
select deptno, count(*) as cnt
, count(case when job = 'SALESMAN' then 1 else 0 end) as sales_cnt
, count(case when job = 'MANAGER' then 1 else 0 end) as manager_cnt
, count(case when job = 'ANALYST' then 1 else 0 end) as analyst_cnt
, count(case when job = 'CLERK' then 1 else 0 end) as clerk_cnt
, count(case when job = 'PRESIDENT' then 1 else 0 end) as president_cnt
from emp
group by deptno;count에 대한 연산을 수행하고자 할 때 1이라는 것은 마치 count(1) 하듯이 의미가 없는 그냥 임의의 숫자이다. (물론 1을 사용하는 것이 보편적이다.)
case when job='SALESMAN' then 1 end 의 경우에는 count 할 대상이 없으면 자동으로 NULL로 인식하지만, 아래처럼 else 0의 조건을 추가하면 NULL 값으로 처리되어야 하는 요소가 count 연산에 포함되어버릴 수 있기 떄문에 주의해야 한다! 따라서 count 연산을 하고 싶을 때도 sum을 통해서 처리하는 것이 바람직하다.
pivoting 시 count에 대한 연산을 수행하고 싶을 때 sum을 활용한다.
-- group by Pivoting시 조건에 따른 건수 계산 시 sum()을 이용
select deptno, count(*) as cnt
, sum(case when job = 'SALESMAN' then 1 else 0 end) as sales_cnt
, sum(case when job = 'MANAGER' then 1 else 0 end) as manager_cnt
, sum(case when job = 'ANALYST' then 1 else 0 end) as analyst_cnt
, sum(case when job = 'CLERK' then 1 else 0 end) as clerk_cnt
, sum(case when job = 'PRESIDENT' then 1 else 0 end) as president_cnt
from emp
group by deptno;<Group by Rollup>
- Rollup과 Cube는 Group by와 함께 사용된다.
- Group by 절에 사용되는 컬럼들에 대해서 추가적인 Group by를 수행한다.
- Rollup은 계층적인 방식으로 Group by 추가 수행
- Cube는 Group by 절에 기재된 컬럼들의 가능한 combination으로 Group by 수행.(따라서 이미 계층적으로 나누어진 요소에 대해서 cube를 활용하면 오히려 데이터가 지저분하게 추출된다.)
GROUP BY ROLLUP(그룹컬럼)
select deptno, job, sum(sal)
from hr.emp
group by rollup(deptno, job)
order by 1, 2;| deptno | job | sum | ||
| 1 | PROFESSOR | 1300 | (deptno, job) group by | |
| 1 | TA | 2450 | ||
| 1 | MANAGER | 5000 | ||
| 1 | NULL | 8750 | (dept) group by | |
| 2 | CLERK | 3000 | (deptno, job) group by | |
| 2 | PROFESSOR | 800 | ||
| 2 | TA | 2975 | ||
| 2 | NULL | 6775 | (dept) group by | |
| 3 | PROFESSOR | 950 | (deptno, job) group by | |
| 3 | TA | 2850 | ||
| 3 | GUARD | 5600 | ||
| 3 | NULL | 9400 | (dept) group by | |
| 3 | NULL | 24925 | () 전체 aggregation | |
rollup 함수의 결과를 보면, (deptno, job) → (dept) → () 순으로 결과값을 도출한다.
Rollup의 경우 Group by 절의 나열된 컬럼수가 N개 이면, Group by는 N+1회 수행
<Group by Cube>
모든 경우의 합계를 구할 때는 CUBE 함수를 사용한다.
약간 모든 경우에 대해서 톺아보고 싶다라는 니즈가 있을 때 사용할 수 있겠지만, 실무에서 많이 쓰이지는 않는다고 한다.
select deptno, job, sum(sal)
from hr.emp
group by cube(deptno, job)
order by 1, 2;| deptno | job | sum | ||
| 1 | PROFESSOR | 1300 | (deptno, job) group by | |
| 1 | TA | 2450 | ||
| 1 | MANAGER | 5000 | ||
| 1 | NULL | 8750 | (dept) group by | |
| 2 | CLERK | 3000 | (deptno, job) group by | |
| 2 | PROFESSOR | 800 | ||
| 2 | TA | 2975 | ||
| 2 | NULL | 6775 | (dept) group by | |
| 3 | PROFESSOR | 950 | (deptno, job) group by | |
| 3 | TA | 2850 | ||
| 3 | GUARD | 5600 | ||
| 3 | NULL | 9400 | (dept) group by | |
| NULL | CLERK | 3000 | (job) group by |
|
| NULL | PROFESSOR | 3050 | ||
| NULL | TA | 8275 | ||
| NULL | MANAGER | 5000 | ||
| NULL | GUARD | 5600 | ||
| 3 | NULL | 24925 | () 전체 aggregation | |
cube 함수의 결과를 보면, (deptno, job) → (dept) → (job) → () 순으로 결과값을 도출한다.
Cube의 경우 Group by 절의 나열된 컬럼수가 N개 이면, Group by는 N^2회 수행
'<p class="coding"> > SQL' 카테고리의 다른 글
| [SQL/ORACLE] 계층적 쿼리(hierarchical Queries) (ING) (0) | 2023.08.25 |
|---|---|
| [SQL/ORACLE] CASE WHEN(IF문) 함수 (0) | 2023.08.24 |
| [SQL/ORACLE] TO_CHAR(DATE, 'MM') = '01' 날짜 함수 (0) | 2023.08.21 |
| [DA] 30일 데이터 분석가 챌린지 2일차 (Analytic SQL - 1) (0) | 2023.07.31 |
| [DA] 데이터 분석가 30일 챌린지 0일차 (1) | 2023.07.29 |

